A while back, I posted optimistically that I’d have some suggestion for handling long code blocks in APEX application exports. I’m sorry to report that I haven’t come up with a solution, but I’ll try to present the problem clearly and suggest some ways that it might be fixed. If you look at a page_#####.sql file created by the export splitter you can see that a common pattern is to take the text blocks you’ve defined, whether SQL, PL/SQL, HTML, JavaScript, help text or page comments and split your text into a series of concatenation statements. New lines get represented as unistr(‘\000a’) and the string builder enforces limits on statement size, meaning your text will be split in difficult to predict ways.
Let’s consider this as an example:![]()
select
e.emp_name,
si.cyb_empdepseq,
si.emp_emp,
si.salary,
si.workdays,
si.new_salary,
si.retro_amount,
si.cyb_dept,
si.start_date start_date,
si.term_date term_date,
si.hours work_hours,
(select
to_char(employee_records.stdHed (si.ear_majmin,si.EAR_APPOINTMENT),'009') from dual) HED,
si.ear_class,
si.ear_activ,
si.ear_time_rpt,
si.ear_payind,
substr(si.his_key,16,1) Hseq,
si.ear_sequence,
si.ear_position,
si.group_increase_key,
decode(si.hr_retro_adjustment, 'Y','Yes',Null,' ') hr_retro_adjustment,
case
when si.ear_period = 'A' then
round((si.new_salary/260.89286)*10,2)
when si.ear_period = 'H' then (si.new_salary * si.ear_hours)*2
when si.ear_period = 'W' then (si.new_salary * 2)
else 0
end biwkly,
nvl(si.ot_retro_amount, 0) ot_retro_amount,
nvl(si.sat_retro_amount, 0) sat_retro_amount
from hradmin.salary_increase si,
hradmin.group_increase gi,
hradmin.employees e
where e.emp_emp = si.emp_emp and
si.group_increase_key = gi.group_increase_key and
gi.group_increase_key = :P919_GROUP_INCREASE_KEY and
si.status = 'P' and
(
(si.cyb_dept in ( select ud.dep
from hrctl.ct_user_depts_er ud
where ud.logon_id = :P919_FU_NAME and
ud.mngmnt_level = 'UPDATE'))
OR :P919_SYS_ALL_RPTS = 'Y'
)
For this post let’s ignore the idiosyncrasies of this query, and focus on how we might expect to compare versions of this query using the APEX application export. The query will be broken into several statements of the form
s:=s||'start of code'||unistr('\000a')||
' next line'||unistr('\000a')||
' last part of this s';
s:=s||'tatement, next statement'||unistr('\000a')
.
.
.
Note the lack of a newline at the end of the first statement, once reconstituted into an item in APEX the above would appear as
start of code
next line
last part of this statement, next statement
So, the string builder is prepared to put a “statement break” inside of a token (above the first use of the word statement is broken up). In the case of the sizable query we’re discussing here it becomes this in the export file:
s:=s||'select '||unistr('\000a')||
' e.emp_name,'||unistr('\000a')||
' si.cyb_empdepseq,'||unistr('\000a')||
' si.emp_emp,'||unistr('\000a')||
' si.salary, '||unistr('\000a')||
' si.workdays, '||unistr('\000a')||
' si.new_salary, '||unistr('\000a')||
' si.retro_amount,'||unistr('\000a')||
' si.cyb_dept,'||unistr('\000a')||
' si.start_date start_date,'||unistr('\000a')||
' si.term_date term_date,'||unistr('\000a')||
' si.hours work_hours,'||unistr('\000a')||
' (select '||unistr('\000a')||
' to_char(employee_records.stdHed (si.ear_majmin,si.EAR_APPOINTMENT),''009'') from dual) HED,'||unistr('\000a')||
'';
s:=s||' si.ear_class, '||unistr('\000a')||
' si.ear_activ,'||unistr('\000a')||
' si.ear_time_rpt,'||unistr('\000a')||
' si.ear_payind,'||unistr('\000a')||
' substr(si.his_key,16,1) Hseq,'||unistr('\000a')||
' si.ear_sequence,'||unistr('\000a')||
' si.ear_position,'||unistr('\000a')||
' si.group_increase_key,'||unistr('\000a')||
' decode(si.hr_retro_adjustment, ''Y'',''Yes'',Null,'' '') hr_retro_adjustment,'||unistr('\000a')||
' case'||unistr('\000a')||
' when si.ear_period = ''A'' then '||unistr('\000a')||
' round((si.new_salary/260.89286)*10,2)'||unistr('\000a')||
' when si.e';
s:=s||'ar_period = ''H'' then (si.new_salary * si.ear_hours)*2'||unistr('\000a')||
' when si.ear_period = ''W'' then (si.new_salary * 2)'||unistr('\000a')||
' else 0'||unistr('\000a')||
' end biwkly,'||unistr('\000a')||
' nvl(si.ot_retro_amount, 0) ot_retro_amount,'||unistr('\000a')||
' nvl(si.sat_retro_amount, 0) sat_retro_amount'||unistr('\000a')||
'from hradmin.salary_increase si,'||unistr('\000a')||
' hradmin.group_increase gi,'||unistr('\000a')||
' hradmin.employees e'||unistr('\000a')||
'where e.emp_emp = si.emp_emp and'||unistr('\000a')||
' si.group_increase_key ';
s:=s||'= gi.group_increase_key and'||unistr('\000a')||
' gi.group_increase_key = :P919_GROUP_INCREASE_KEY and'||unistr('\000a')||
' si.status = ''P'' and '||unistr('\000a')||
' ('||unistr('\000a')||
' (si.cyb_dept in ( select ud.dep '||unistr('\000a')||
' from hrctl.ct_user_depts_er ud'||unistr('\000a')||
' where ud.logon_id = :P919_FU_NAME and'||unistr('\000a')||
' ud.mngmnt_level = ''UPDATE''))'||unistr('\000a')||
' OR :P919_SYS_ALL_RPTS = ''Y'''||unistr('\000a')||
' )'||unistr('\000a')||
'';
So you can clearly see where it’s inserted a “statement break” in the middle of a line, or worse, in the middle of a token. You can see that line 29, and line 31 contain two parts of a single si.ear_period token.
Further, where these “statement breaks” occur will change as your code changes. Add a comment to this query, or restructure it to consistently use case instead of decode, and now the line-wise compare provided by version control tools starts reporting false positives.
To demonstrate I’ll change the code to this:
select
e.emp_name,
si.cyb_empdepseq,
si.emp_emp,
si.salary,
si.workdays,
si.new_salary,
si.retro_amount,
si.cyb_dept,
si.start_date start_date,
si.term_date term_date,
si.hours work_hours,
to_char(employee_records.stdHed(si.ear_majmin,si.EAR_APPOINTMENT),'009') HED,
si.ear_class,
si.ear_activ,
si.ear_time_rpt,
si.ear_payind,
substr(si.his_key,16,1) Hseq,
si.ear_sequence,
si.ear_position,
si.group_increase_key,
case
when si.hr_retro_adjustment = 'Y' THEN 'Yes'
WHEN si.hr_retro_adjustment IS NULL THEN ' '
end hr_retro_adjustment,
case
when si.ear_period = 'A' then
round((si.new_salary/260.89286)*10,2)
when si.ear_period = 'H' then (si.new_salary * si.ear_hours)*2
when si.ear_period = 'W' then (si.new_salary * 2)
else 0
end biwkly,
nvl(si.ot_retro_amount, 0) ot_retro_amount,
nvl(si.sat_retro_amount, 0) sat_retro_amount
from hradmin.salary_increase si,
hradmin.group_increase gi,
hradmin.employees e
where e.emp_emp = si.emp_emp and
si.group_increase_key = gi.group_increase_key and
gi.group_increase_key = :P919_GROUP_INCREASE_KEY and
si.status = 'P' and
(
(si.cyb_dept in ( select ud.dep
from hrctl.ct_user_depts_er ud
where ud.logon_id = :P919_FU_NAME and
ud.mngmnt_level = 'UPDATE'))
OR :P919_SYS_ALL_RPTS = 'Y'
)
Hoping to see a diff like (click to zoom):
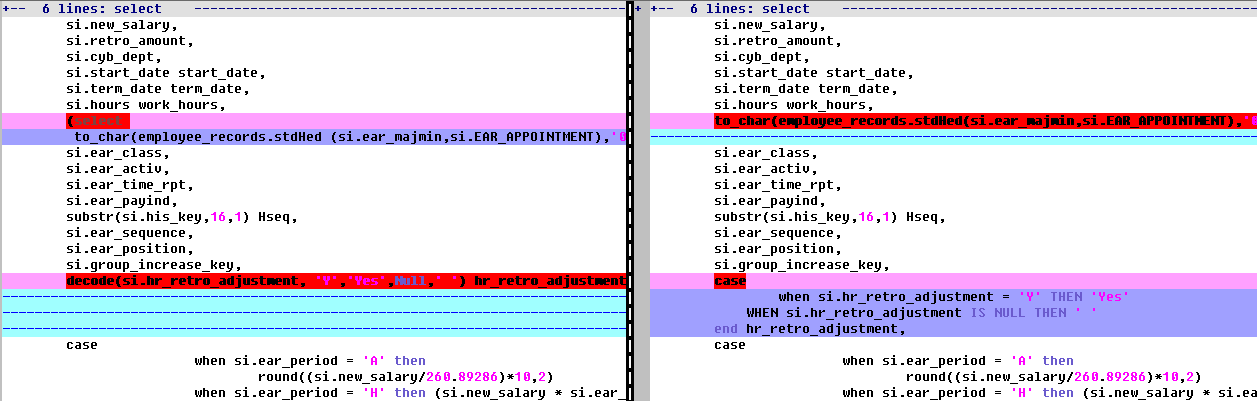
Viewing the differences of just the queries in vimdiff
Instead after performing an application export, and viewing a SVN diff it looks more like this (click to zoom):
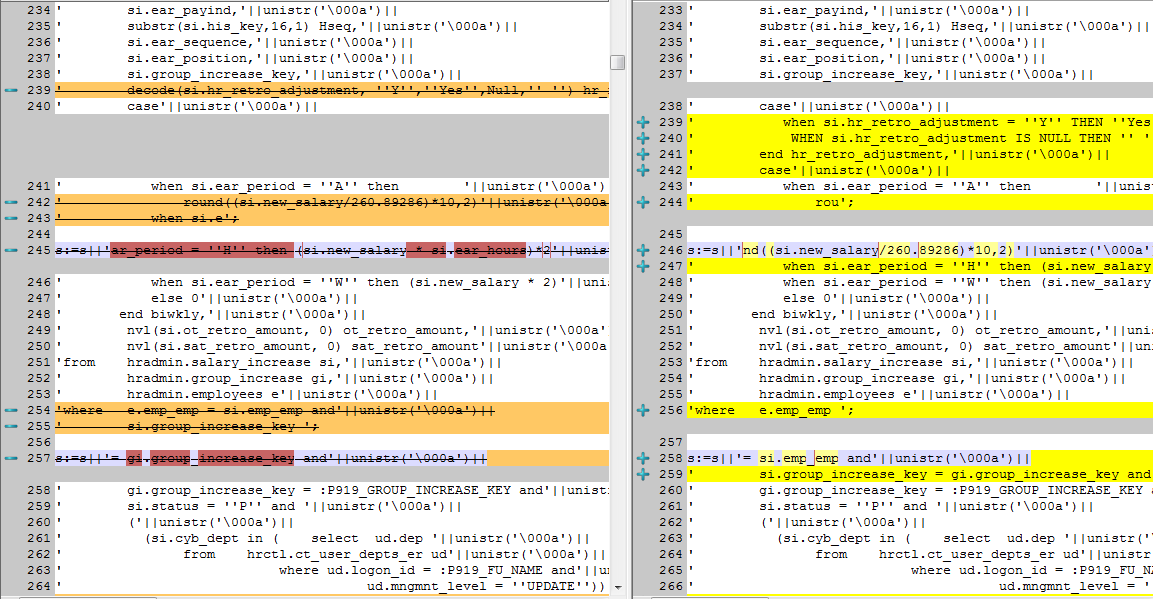
Diff After Export
The new export has introduced a “statement break” in the middle of a condition (lines 256 & 258 on the right). On lines 242-259 (on the right) it’s reporting changes that are entirely the result of changes above shifting this code downward. No changes were made to the join conditions, but on a commit and again on a merge you’d be forced to review this non-change.
Advice
So for now your best bet is likely to avoid using long blocks whenever possible. Failing that, ensure you perform frequent commits. So, if I know that page_00919.sql was changed to remove decodes then got committed to my branch and not changed again I can be confident that the changes I’ll see when merging back into the trunk are all intentional. In this case, I’d run my application dump and split script before committing to ensure I know all the changes that I want are present and understood.
Perhaps this should be reported as a bug/feature request to the apex team. The exporter could be complicated to either disallow mid-token “statement breaks”, or even make each source line it’s own concatenation statement. Having each line as it’s own statement would likely be massively inefficient, but in my opinion the value add of easier change management would make up for it.
If this issue affects you, or changing this behaviour just seems like a good idea please consider voting for my feature request “Alter Export String Splitting Behaviour to Enhance Versioning” at the Oracle Application Express Feature Requests application.
Hi Alan,
one of the features that I am working on for 5.0 is optimization of the export file format. Things look quite good, but this is all work in progress and the safe harbour statement applies (IOW, everything may change before we will actually ship 5.0, so don’t rely on what you hear or read from me).
That being said, in the current 5.0 trunk version, exported files are about 30% smaller and the breaks you mentioned are gone. Your example would look like
…
wwv_flow_api.create_report_region(
…
,p_source=>’start of code’
||wwv_flow.LF||’ next line’
||wwv_flow.LF||’ last part of this statement, next statement’
||wwv_flow.LF||’…’
,p_source_type=>’SQL_QUERY’
…
There have also been some changes to the Splitter, since you mentioned that tool. It generates less files, as I see no need for a separate one for each individual shared component. For example, instead of one file for each LOV, there is only f100/application/shared_components/user_interface/lovs.sql now. Not many people seem to be using the Splitter, I’d be interested in your opinion on this change.
Regards,
Christian
Hi Christian,
That’s fantastic news! I certainly hope the export improvements make it to the released code, and if you need a beta tester you know where to find me!
On your query about merging the LOVs (and other shared components) my feeling is that the granularity of the split up export is where the value comes from. Identifying changes in the monolithic export i.e. f100.sql can be bit trying, at least presently as you need to identify the s:=|p:=|h:= statement set then track down in the file to find the wwv_flow_api call that uses the defined varchar2. The changes you’re discussing would make the human readability better.
One thing I value about the split export is how well it works with the shell integration provided by some version control tools. With the split up LOVs, I can at a glance see that I’m merging a change to bargunit_lov.sql, and that the rest of my LOVs aren’t affected. I’d be sorry to see this functionality go, but I’d give up for something that tries harder to keep a line I’ve entered as a line in the export.
Finally; I don’t have any data to back this up…But I suspect SQL Developer and Toad’s handling of the install.sql file has been a major tripping point for people using the splitter. I touched on this briefly in my post on Automating APEX Export for SVN, it’s under the heading “Usability of the Split Up Export”. So adoption could possibly see an uptick if SQL Developer processed @includes the same way SQL*Plus does, or if the individual component .sql files were split more correctly. I suppose another option would be to include batch/bash/wsh scripts to concatenate all the @ files into a new monolithic import. NB – I will sometimes perform an export/split, then revert changes to components I don’t want to include in a changeset or promotion.
Cheers,
Alan
Hi Alan,
thanks, very interesting. There are 2 reasons why I want to reduce the number of files. First, some people complained that the splitter output is confusing, that it produces too many files. You seem to think otherwise, I’ll try to find a compromise. Second, each PL/SQL block causes round trips to the database during install. Less blocks means the install is faster. Good news is probably that the splitter now respects PL/SQL block ends, i.e. in principle, the files could be installed independently (obviously, there are dependencies between the objects, though).
Regards,
Christian